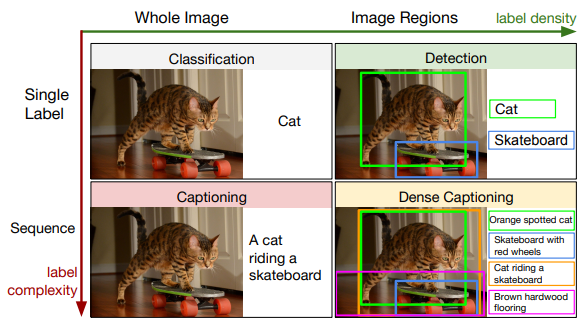
Dense captioning is a task which requires a computer vision system to both localize and describe salient regions in images in natural language. The dense captioning task generalizes object detection when the descriptions consist of a single word, and Image Captioning when one predicted region covers the full image. “DenseCap: Fully Convolutional Localization Networks for Dense Captioning” by Karpathy et. al. proposed a Fully Convolutional Localization Network (FCLN) architecture that processes an image with a single, efficient forward pass, requires no external regions proposals, and can be trained end-to-end with a single round of optimization. The architecture is composed of a Convolutional Network, a novel dense localization layer, and Recurrent Neural Network language model that generates the label sequences. In this project, we tried two things. First was to reproduce the results obtained by the authors to get familiar with the codebase. Second, we replaced the test time Non-Maximal Supression with a Tyrolean Network as described in “A convnet for non-maximum suppression” by Hosang et. al. We were able to obtain a slight increase in the Mean Average Precision of DenseCap compared to our run of the original code.
Palash Chauhan
Masters Student in Computer Science
My research interests include distributed sytems, machine learning and their intersection.